دادهها امروز نقش بسیار مهمی در صنایع مختلف، اقتصاد و حتی سیاست دارند. بنابراین، پردازش آنها از اهمیت زیادی برخوردار است. در این مقاله، قصد داریم درباره پیشپردازش داده صحبت کنیم که جزئی از آمادهسازی دادهها به شمار میرود. در واقع، هر نوع پردازشی که بر روی دادههای خام انجام میشود، آنها را برای پردازشهای بعدی آماده میکند.
شاید درباره دادهکاوی مطالبی خوانده باشید، در حالی که تکنیکهای پیشپردازش دادهها برای آموزش مدلهای یادگیری ماشین و هوش مصنوعی استفاده میشوند. به همین دلیل، در ادامه ابزارهای پیشپردازش داده را معرفی کرده و سپس به بررسی مراحل کلیدی آن میپردازیم.
ابزارهای پیش پردازش داده
از آنجایی که هر نوع تجزیه و تحلیل داده، علم داده (Data Science) یا توسعه هوش مصنوعی به نوعی از پیشپردازش داده نیاز دارد تا نتایج قابل اعتماد، دقیق و قوی برای برنامههای کاربردی سازمانی ارائه دهد، میتوان از ابزارها و روشهای مختلفی برای پیشپردازش دادهها استفاده کرد. این ابزارها و روشها به ما کمک میکنند تا دادههای خام را به فرمتی تبدیل کنیم که برای مدلهای یادگیری ماشین و سایر تجزیه و تحلیلها مناسب باشد.
در ادامه، به برخی از ابزارها و روشهای متداول برای پیشپردازش دادهها اشاره خواهیم کرد:
- یک زیرمجموعه از جمعیت بزرگی از دادهها را به عنوان نمونه انتخاب میکنیم.
- دادههای خام برای تولید یک ورودی واحد دستکاری میشود که به اصطلاح به این فرایند تبدیل میگوییم.
- نویز را از دادهها حذف میکنیم.
-
در فرآیند پیشپردازش دادهها، یکی از مراحل کلیدی مدیریت مقادیر از دست رفته است. برای این کار، ابتدا دادههای آماری مرتبط را ترکیب میکنیم و سپس پس از انتخاب یک زیرمجموعه ویژگی مرتبط که در یک زمینه خاص اهمیت دارد، این ویژگیها را استخراج میکنیم.
به این ترتیب، میتوانیم دادهها را به شکلی ساماندهی کنیم که شامل اطلاعات کافی و مرتبط باشد و برای تحلیلها و مدلهای یادگیری ماشین مناسب باشد. این روش به ما کمک میکند تا کیفیت دادهها را بهبود ببخشیم و از انحرافات ناشی از مقادیر گمشده جلوگیری کنیم.

ممکن است از خود بپرسید که پیش پردازش دادهها چرا مهم است؟ در پاسخ، اینطور میتوان گفت که یک مجموعه داده اغلب فیلدهای جداگانه ندارند و حاوی خطاهای ورودی هستند. برخی از دادهها تکراری ثبت شدهاند و نامهای متفاوتی برای توصیفشان وجود دارد. از این رو دادههایی که برای آموزش یادگیری ماشین یا الگوریتمهای یادگیری عمیق استفاده میشوند میبایست به طور خودکار پیش پردازش شوند تا نتیجه درستی از آنها حاصل شود.
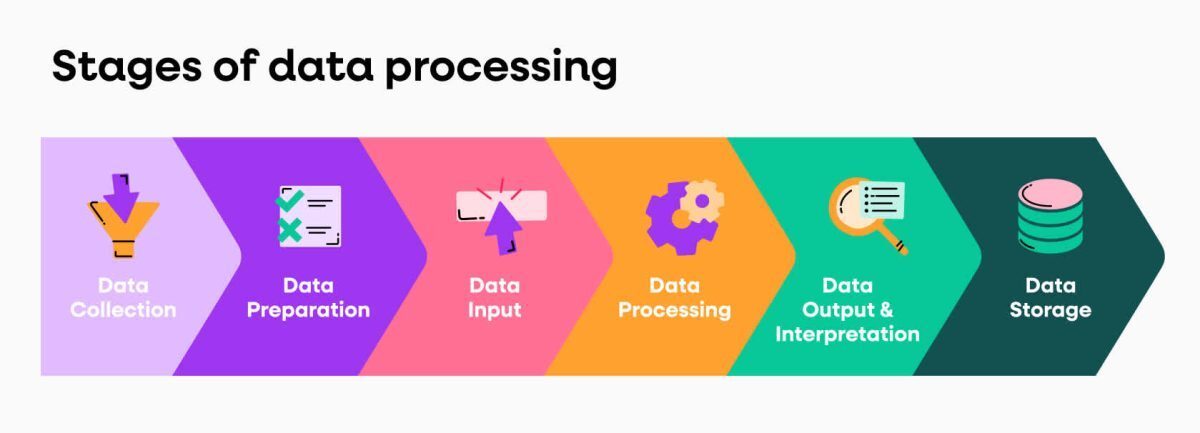
مراحل کلیدی در پیش پردازش داده
مراحل پیش پردازش داده را میتوان به صورت زیر دستهبندی کرد:
- پروفایل داده: مرحله پروفایل دادهها با بررسی دادههای موجود و ویژگیهای آن شروع میشود. در واقع، فرآیند بررسی، تجزیه و تحلیل دادهها برای جمعآوری آمار در مورد کیفیت آن است. متخصصان داده، مجموعههای دادهای را شناسایی و ویژگیهای مهم آن را فهرستبندی میکنند. در نهایت فرضیهای از ویژگیهایی را تشکیل میدهند که ممکن است برای تحلیل پیشنهادی یا یادگیری ماشین مرتبط باشند. در این مرحله، ارتباط منابع داده با مفاهیم کسب و کار و همچنین کتابخانههای پیش پردازش پایتون مشخص میشود.
- پاکسازی دادهها: حذف دادههای اضافی، پر کردن دادههای از دست رفته یا اطمینان از مناسب بودن دادههای خام اهمیت ویژهای در پیش پردازش دادهها دارد.
- کاهش دادهها: برای کاهش دادهها از تکنیکهایی مانند تجزیه و تحلیل مؤلفههای اصلی برای تبدیل دادههای خام به شکل سادهتر مناسب برای موارد استفاده خاص استفاده میشود.
- تبدیل داده: این مرحله مواردی مانند ساختار دادن به دادههای بدون ساختار و تمرکز روی آنها را شامل میشود.
- غنی سازی دادهها: در مرحله غنی سازی، متخصصان داده، ویژگیهای مختلفی را بر روی دادهها اعمال میکنند تا تبدیلهای مورد نظر به دست آید. نتیجه این مرحله، باید مجموعه دادهای باشد که برای دستیابی به تعادل بهینه بین زمان آموزش برای یک مدل جدید و محاسبات مورد نیاز سازماندهی شده است.
- اعتبار سنجی دادهها: در این مرحله دادهها به دو مجموعه تقسیم میشوند. اولین مجموعه برای آموزش یک مدل یادگیری ماشین یا یادگیری عمیق استفاده میشود. مجموعه دوم دادههای آزمایشی است که برای سنجش دقت و استحکام مدل به دست آمده استفاده میشود. در مرحله دوم، به شناسایی هرگونه مشکل در تمیز کردن و مهندسی ویژگی دادهها کمک میشود. اگر متخصصان داده از نتایج راضی باشند، میتوانند وظیفه پیش پردازش را به یک مهندس داده سوق دهند که چگونگی مقیاسبندی آن را برای تولید بیابد. در غیر این صورت، متخصصان داده میتوانند به عقب برگردند و تغییراتی در نحوه اجرای مراحل پاکسازی دادهها و مهندسی ویژگیها ایجاد کنند.

در نهایت، پیشپردازش دادهها یکی از مراحل کلیدی و مهم در هوش مصنوعی به شمار میرود. به این صورت که لاگها و دادههای رویدادی خام که از سیستمهای اطلاعاتی جمعآوری شدهاند، پس از انجام عملیات پاکسازی و استانداردسازی، آماده تجزیه و تحلیل توسط الگوریتمها و روشهای کشف فرآیند میشوند. پس از آمادهسازی دادهها، میتوان فرآیندکاوی را بر روی آنها اعمال کرده و الگوهایی برای عملکرد بهتر و بهرهوری فرایندهای کسب و کار استخراج نمود.